
I recently wrote this piece for Corndel and Nottingham University Business School about how non-technical leaders can help their organisations become more data-driven, and the skills that will help them.
Duncan R Shaw – The qualitative data scientist
How to create value from your data: the latest ideas on customer loyalty, data-driven strategy and journey-based thinking.
I recently wrote this piece for Corndel and Nottingham University Business School about how non-technical leaders can help their organisations become more data-driven, and the skills that will help them.

(A version of this article without the links, recently appeared in the University of Nottingham Alumni Newsletter)
Many companies are rushing to use AI technology. But first things first. Where should we start?
There are tasks that AIs do much better than humans… but there are tasks where humans remain light years ahead of AIs. Understanding which tasks suit AI capabilities, and which tasks are best left to humans can make or break your company’s planning for the next decade. Understanding how to create completely new capabilities, busines processes and busines models? That’s where the fun really starts.
Where to use AI in your business
Artificial Intelligence technologies are great at finding useful patterns in large amounts of data. That is what is useful about them. We need AIs because humans have very limited information processing capacity. Humans get ‘information overload’. We cannot hold that much data in our head, and we cannot process data quickly. We achieve infinitely more when we use AIs to look for patterns in massive datasets – these patterns act as cheat sheets for those datasets.
AI-generated patterns organise data for us. This looks like indexes, contents pages and look-up tables – I recently explained more about how AI-generated patterns in this article.

When to use AI-generated patterns in your business – and when not to
If AIs generate patterns – then when should we use these patterns? The opportunity is simple. To use AI technology for revolution, not evolution. Don’t just automate the old ways of doing things – why not dream up something new?
One definition of resilience that keeps on coming up in my research is that resilience is about bouncing back better than you were before. COVID-19 is the ultimate burning platform – the push for change that we cannot ignore.
So first, focus the power of AI technology on areas which must change right now. What do your customers really really need? What are your staff crying out for?
Second, don’t just make a better version of your old ways of doing things. Take this opportunity to check if what you are doing can have even better outcomes – or if it’s actually needed at all.
For example, you could spend time creating an AI to develop a complex, super personalised and fully automated customer complaints system.
Alternatively, you could simply use your existing data to find the pattern which shows which 10% of the problems in your business cause 80% of the complaints. The same pattern recognition process might also identify which of those 80% of complaints affect your best – and future best – customers.
Or why not pan back even more? Look at the big picture. What is the pattern which connects the most damaging problems in your customers’ businesses with the solutions capabilities that AI can offer your business?

AI enables completely new activities and capabilities.
AIs give your firm new capabilities – like AI vision, speech recognition and personalised recommendations. They lighten the load and they free up humans to do something else.
Machine vision systems identify potential cancer cells. This frees up radiologists to focus on what to do next. In our homes, smart speakers use AIs like Alexa, Siri and Google Assistant to help us in our busy lives. The vast amount of data being generated by Internet of Things devices is too much for humans to analyse on their own. So, organisations really need AIs to support their staff.
Your staff are your scarcest, most valuable resource. It seems odd but your staff are actually the bottleneck which holds back growth. I mean, if you could double the talent in your firm, then you could more than double your growth rate. The better you use and support your staff then the more your business will flourish.
I’m often asked: “What can AIs do better than humans?”
To answer that question, it is best to turn it on it’s head. What are the things that AIs CAN’T do?
AIs do not have intuition. They are not, themselves, genuinely creative. They cannot think critically; and they do not have empathy.
The reasons why AIs cannot do these things helps us see where to use them – and it helps your own job security.
The implication of all of this is that AIs join the team. They do not replace the team. It’s best to think of AIs as new team members (very focused team members…). Deciding how to use your staff in the best possible way is the same as deciding which businesses processes should incorporate AIs.

AIs enable completely new business processes
The saying “Quantity has a quality all of its own” is found Marxist theory and is falsely attributed to Stalin. It’s roots are in ancient Greek philosophy – and it’s highly applicable to 21st century AI technologies.
It turns out that as a thing increases in number or speed, then the qualitative effect produced by that thing radically changes.
Machine learning technologies can integrate many ‘experiments’ – and pick winners in real-time. The autocomplete feature in the Google search box suggests search terms instantaneously, as you are typing words in.
AIs might take time to learn patterns, and they might need expensive retraining. But applying these patterns can be astoundingly fast. Processes can be reengineered on a much more granular level; or even ‘on the fly’- as happens with the optimisation of workflows and layout in Amazon’s sorting centres. Which is a game changer – it’s a process which reengineers a process.
The implication is that AIs can move beyond discrete events to create qualitatively different outcomes. Like new products, business processes and services. AIs can optimise multiple dependencies, like stages in business processes and locations in journeys, in real-time.
AIs enables completely new business models
This is what business model disruption is all about. A business model is a recipe for solving customers’ problems with any capabilities that you can access. New capabilities lead to new business models – which include new problems being solved, or new customers being helped.
New bundles of capabilities produce new ways to create value, as well as new types of value to be produced. This is beautifully illustrated by the capability to fit a powerful computer into a mobile phone, which has led to a multitude of new services based on using them when and where you want to.
New AI-based business models hide complexity for customers – sometimes to the extent that completely new things become possible. Spotify achieves this: the service is the ‘music I love, but that I do not need to choose, or even know that it exists’.
Paying a human to learn someone’s musical tastes; and then pick and produce personalised musical performances is not scalable. But Spotify did it – using AIs.
The implication is that AIs can create totally new types of value – not just new ways of producing value.

How to start implementing AI in your business
The starting point for implementing AI is to change your business strategy to use AI in the best way. Start by building an AI capability in your organisation. Implement the processes which produce AI-as-a-service; to create an AI operation. This means getting the right people and skills mix; and a suitable organisational design, culture, and metric system.
This takes time – but focused projects can be done very quickly, especially when you (temporarily) bring in external expertise.
The best AI tech in the world is just waiting to be rented – like any other cloud service.
The next step is to adjust your business model to make use of these AI capabilities, and make sure your company strategy reflects this.
After this? You need to deploy AI in your company. You can use Journey Analysis (which is similar to business process mapping) to make a use case plan for employing AI and digital capabilities. The aim here isn’t merely to sell the project to the CEO; but to finely plan resources needed, stakeholders to engage, deliverables to measure and successes to broadcast when they are met.
In parallel with the process view that a Journey Analysis gives you, think about your organisation’s design, and the projects that suit your organisational level of data. Or what data you can buy-in.
And all this needs a road map and business case to pitch to your Board/CEO – right at the start.
Have a good journey!
My new post on LinkedIn explains how AI’s help us by finding patterns in massive datasets and how these patterns actually help us to run our businesses. Clarifying this helps us to design better AIs and to use them more successfully.


My new post on LinkedIn gives a few tips on the sorts of jobs that will be created as we work more and more with AIs.

My new post on LinkedIn gives a few tips on the skills you’ll need as more AIs enter your workplace.

My new post on LinkedIn gives a few tips on governance. How your special perspective can help you to build a well-organised ecosystem.

My new post on LinkedIn is about how looking for the right data is like looking for a needle in a haystack. But we found a way to match data generators with data users – even for unpredictable data needs.

My new blog on LinkedIn is about the organisations which will deal with all the data that our AIs will need to work well. How do we make sure these organisations do not stray?
 One type of AI software uses neural nets to recognise patterns in data – and it’s increasingly being used by tech firms like Google and IBM. This type of AI is good at spotting patterns but there is no way to explain why it does so. Which is a bit of a problem when the decisions need to be fully accountable and explainable.
One type of AI software uses neural nets to recognise patterns in data – and it’s increasingly being used by tech firms like Google and IBM. This type of AI is good at spotting patterns but there is no way to explain why it does so. Which is a bit of a problem when the decisions need to be fully accountable and explainable.
I could have called this post ‘One thing you cannot do with AI at the moment. There are many things that AIs are helping businesses with right now. But if your firm is going to use them then it’s important to know their limitations.
I remember doing my maths homework once and getting low marks even though I got the right answers. The reason I lost marks was because I didn’t show my working out.
Sometimes the way that the answer is produced needs to be clear as well.
It is like that with some AI technologies right now. There are types machine learning AI that are amazing at recognising patterns but there is no way to explain how they do it.
This lack of explainability can be a real barrier. For example, would you trust a military AI robot armed with machine guns and other weapons if you weren’t sure why it would use them?
Or in medicine, where certain treatments carry their own risks or other costs. Medics need to understand why an AI diagnosis had been made.
Or in law, where early versions of the EU’s General Data Protection Regulation (GDPR) introduce a “right to explanation” for decisions based on people’s data.
The problem is that for some types of machine learning, called “Deep Learning”, it is inherently difficult to understand how the software makes a decision.
Deep Learning technology uses software that mimics layers and layers of artificial neurons – neural networks. The different levels of layers are taught to recognise different levels of abstraction in images, sounds or whatever dataset they are trained with.
Lower level layers recognise simpler things and higher level layers recognise more complicated higher level structures. A bit like lower level staff working on the details and higher level managers dealing with the bigger picture.
Developers train the software by showing it examples of what they want to it recognise, they call this ‘training data’. The layers of neural networks link up in different ways until the inputs and the outputs in the training data line up. That’s what is mean by ‘learning’.
But neural network AIs are like ‘black boxes’. Yes, it is possible to find out exactly how the neurons are connected up to guess an output from a given input. But a map of these connections does not explain why these specific inputs create these specific outputs.
Neural network AIs like Google’s Deep Mind are being used to diagnose illnesses. And IBM’s Watson helps firms find patterns in their data and powers chatbots and virtual assistants.
But on its own a neural network AI cannot justify the pattern it finds. Knowing how the neurons are connected up does not tell us why we should use the pattern. These types of AIs just imitate their training data, they do not explain.
The problem is that lack of accountability and explainability. Some services need proof, provenance or a paper trail. For example, difficult legal rulings or risky medical decisions need some sort of justification before action is taken.
Sometimes transparency is required when making decisions. Or maybe we just need to generate a range of different options.
However, there are some possible solutions. Perhaps a neural network AI cannot tell us how it decides something. But we can give it some operating rules. These could be like the metal cages that shielded production workers from the uncertain movements of early industrial robots. As long as a person did not move into the volume that the robot could move through then they would be safe.
Like safe paces to cross a road. Operating rules would be like rules of warfare, ground rules, policy and safety guidelines. Structures that limited the extent of decisions when the details of why the decisions are made are not known.
A similar idea is to test the AI to understand the structure of what sort of decisions it might make. Sort of the reverse of the first idea. You could use one AI to test another but feeding it huge numbers of problems to get a feel for the responses that it would provide.
Another idea is to work the AI in reverse to get an indication of how it operates. Like this picture of an antelope generated by Google’s Deep Dream AI.
The antelope image that was generated by the AI shows a little about how the AI software considers to be separate objects in the original picture.
For example, the AI recognises that both antelopes are separate from their background – although the horns on the right hand antelope seem to extend and merge into the background.
Also, there is a small vertical line between the legs of the left hand antelope. This seems to be an artefact of the AI software rather than a part of the original photo. And knowing biases like that helps us to understand what an AI might do even if we do not know why.
But whatever the eventual solution, the fact that some AIs lose marks for not showing their working out highlights that there are many different types of AIs and they each have their strengths and weaknesses.

My new article on Linkedin Pulse suggests how firms that make IoT products and services could build their own IoT ecosystems and how they could persuade other firms to join.

My new article on Linkedin Pulse looks at the implications of how the sensors on modern cars can tell manufactures where you drive, how you drive and when it might be about to breakdown. This data could be a massive help to car repair garages, insurers and other firms. But manufactures might want to charge for it and this might increase the cost of servicing your car. So how will firms partner together?
My research suggests strategies for building Internet of Things (IoT) ecosystems in the car industry and other IoT product industries.
The success of the Internet of Things (IoT) depends on sharing data between different devices but it needs to be done appropriately. But there are some brand new technologies that might support appropriate data sharing and they can do it on a massive scale.

Sharing (data) is good for us. The more we share then the more perspectives we have on any given consumer or any given problem. In retail this means getting a better understanding of what customers need even before they do. For the IoT this means combining the sensors and abilities of many devices to get a fuller picture of what’s needed and having more options on how to do it.
Firms that manufacture IoT products only get direct data from the customers that use their products. One device only ‘experiences’ a part of a customer’s life. To get a fuller understanding of a single customer’s life different devices need to share data, preferably devices that help the same customers in different ways.
The classic example is a shopping app on your phone that uses data from your refrigerator to suggest recipes based on what you actually have in stock. Or a firm that uses data from all the devices that it has sold in the past to give advice to specific customers, like Waze uses crowd sourced data on traffic jams to warn its users.
But really useful data can come from external sources.
Just like good feedback and useful suggestions, external information is more likely to give you a new perspective. So devices that share data with many other devices will tend to get more useful information and make better decisions. Decisions that are either more personalised, because of complementary information about the same user, or decisions that are chosen from more options, because of information on more user situations.
However, the problem is that firms don’t like to share with other firms for commercial reasons. More importantly, firms can’t just share customer data with any firm that they want to because of data protection legislation. How would you feel if your data was shared with anyone and everyone?
Of course you need some physical way of sharing the data, like Temboo’s stack or a platform like EVRYTHNG. But you also need some rules too.
The problem is that sharing data makes for better user services but sharing data must be done appropriately.
I’ve blogged about this before here, here and here. But now I’ve figured out how to do it using new technologies like smart contracts and blockchains.
Here’s the solution: if you want to share your data, meaning sell it or even just release the value in it for free, then first you need to stop talking about ‘data’. Be more specific. Being very specific is the key to reducing data sharing sensitivities.
If you ask me whether you can share all my data with everyone, everywhere and let them use it as they choose and pass it on to whoever they want to, forever. Then I’m going to get a bit tense.
But if you tell me exactly how you want to use it, why you need to use it, who else might get a look at it and what they are entitled to do with – either the data or the products of the data – and how long this is for. Then I will be much more open to your suggestions.
I still won’t give you my medical data so that your algorithm can charge me a higher insurance premium. And I hate it when it feels like my data is being used to sense when I will pay more for dodgy science fiction books on my Kindle or more expensive airline tickets.
But generally speaking a highly specific definition use of will remove a lot of my reservations. And real anonymisation will remove all of them. Q: who owns this anonymous data? A: dunno.
So how can we apply this to the IoT one devices at a time?
It is relatively easy to run a loyalty card programme because it is centralised and largely automated. But the IoT needs to be decentralised. If every device asks you or its manufacturer for permissions and instructions every time it needs data – or when is asked to supply data – then the IoT will not get very sophisticated.
So how do we ensure highly specific data sharing? Well, we need to design smartness into the IoT. So let’s use smart contracts.
Smart contracts are a mixture of contract law and software. The rules that govern a relationship between two parties are embedded in the software that facilitates the same relationship. To put it another way, the contractual terms are embedded in the thing that they govern. So they control it to help ensure that agreements are kept.
Software is made of rules and instructions for use but contracts also need proofs of things like identity, ownership, endorsements, permissions and rights to do things. And they need to be cryptographically secured, decentralised and machine readable so that every device can automatically ‘negotiate’ with other devices as required.
Fortunately all this can be written into blockchains, the distributed and cryptographically encoded databases that underlie digital currencies. In principle, the data sharing rules for each device can be broadly pre-specified; for consuming third-party data as well for supplying data.
Smart contracts could automate a multitude of interactions between IoT devices and pre-specify what constitutes appropriate behaviour in different circumstances. Automation is important because the more devices the better and the more granular the interaction then the smoother the service. Pre-specification is important because you do not know which devices your devices will meet.
The self-world of an IoT device is made up of all that it senses and all that it can do. All its sensor data and all its capabilities to change the physical world. Each device has different sensors and effectors, so many diverse devices working together can help each other.
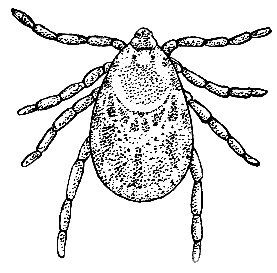
Jakob von Uexküll’s idea of an ‘umwelt’ is really useful for understanding the Internet of Things (IoT), either for building a single IoT device, or an IoT app, or for building a whole IoT ecosystem.
If you want to design a single IoT device or a single IoT app then you need to know how it fits into one or more ecosystems. It cannot exist on it’s own. An IoT device on its own is just a device. The potential of the IoT lies in the combined capabilities of many devices working together.
If you want to design an IoT ecosystem – maybe because you want to build a platform, a network or something to help lots of people – then you need to understand how the devices in the ecosystem can help each other.
Whether you are wondering how an individual device can work with other devices or how can many devices all work together, then the umwelt idea helps to answer both these questions.
What exactly is an umwelt?
An umwelt is the ‘self-world’ of a machine, a person or an animal. It is a combination of all that it senses by plus all that it can do to change it self-world.
For example, a female wood tick hangs in a bush waiting for a deer or other prey. When it senses the butyric acid produced by all mammals, it lets go of its perch. If it lands on some fur this impact is the input trigger that makes the tick scurry around. If it then senses a warm membrane, like skin, then that input triggers piecing and sucking actions.
The tick’s self-world has three input signals and three output action. Its sensors are so limited that any warm membrane will trigger piecing and sucking. A rubber sheet holding warm glycerine will give the same input signal and generate the same action as skin.
Humans can see that ticks usually pierce and suck mammals’ blood through skin but the ticks’ actual sensors and are more limited that what humans see and understand. Ticks have a very different umwelt to humans, just as every IoT device has its own special sensors and effectors.
Von Uexkull also helps us to understand how every IoT device has its own perspective. He wrote about the ‘magic journey’ of animals. For example, ticks can survive for many years just hanging in wait for the scent of butyric acid; some birds migrate each year from pole to pole; and some insects just move from one end of a cereal gran to another.
The umwelts of animals are different because of their different sensors and effectors. And what they sense and do is strung together into the very different journeys of their lives. So the magic journeys of animals are hugely different in terms of timescale and distance. This gives each species a very different perspective on the same events.
Devices and applications have different sensors and effectors – different umwelts.
What devices and applications sense is subjective and specific to each one. For example, a phone might have special information because it monitors a particular person’s physical activity levels. That phone has the right sensors – accelerometers and a clock – and only that one is in the right place at the right time to record that user.
Also, the things different devices can do are subjective and specific to them because they all have different capabilities. Phones use screens, audio speakers, vibrators and other effectors to influence you. Cars do this as well but they can also move you. Websites can inform and guide you. And rowing machines can simulate different water conditions or just say when your exercise time has finished.
Devices and applications have different sensors and effectors. So if devices work with other devices they can get access to different information and different ways to help a user.
The secret to successful IoT services
No single device has enough information to help you with anything but the simplest of problems. For example, apps are usually highly specific in what they are for and they usually need you to supply most of the information. And no single device has enough capabilities to guide you using multiple ‘touch points’ and to deal with most of the problems itself.
For example, Sat Navs and GPS apps are best when they integrate lots of data sources and they are indispensable when then they can actually do something about the different problems that come up. A sensible shopper commonly looks at several different retailers’ websites using several different devices, plus some in-store checking, in their shopping journey to buy a high value item.
Bigger problems are solved by solving smaller problems one after the other in a sort of ‘journey’. And each smaller problem requires different information and different capabilities. The more complicated the problem is then the more complicated is the service that it solves. But a single device is too limited on its own. It can only know about its own self-world and it can only change it’s own self-world in a small number of ways.
Real-word problems are complicated. The more that devices can combine their information-sensing capabilities and their abilities the change the real world, then the more sophisticated are the IoT services that they can jointly produce.
The IoT offers the potential for ‘personal Sat Navs’ that use information from a network of sources and that employ a variety of ways to smooth and guide each user’s journey. Journeys in shopping, travelling, education, recreation and work – IoT services can solve the collections of serial problems that we call life.
If you want to design a single IoT device or a single IoT app then think about what extra data you need and what extra capabilities would complement whatever your device or app can do on its own. How do these change along the course of each user’s journey?
If you want to design an IoT ecosystem then think about the mix of data and capabilities that you have access to. Do the devices that produce them work smoothly together and how do they combine to fit the needs of the different users? Including the needs of the devices themselves.
For the Internet of Things (IoT) to function well then lots of IoT devices need to work together properly. But how can these other devices be trusted? Blockchain technologies might be the answer.

The idea of any device with a chip and a web connection working with any other device has lots of potential. At home your freezer could partner with your cooker to swap ideas for meals and precise cooking instructions that are based on what is actually in your freezer and how your cooker best heats up food.
At work your office devices could work together to help you and your colleagues. Your car could be operated by your phone and vice versa. The Internet Of Everything means any device could potentially work very closely with any other device.
The trust problem
But what happens if one of these devices has been hacked? Maybe your phone has a virus. Or if you need your car to communicate with someone else’s car – to organise routes or a place to meet up – then maybe the other car will infect yours? So how can we make the IoT secure?
The problem of ‘trust’ is bigger than just avoiding infection. How can you trust a device that you do not own or control? Maybe a toll booth will charge you incorrectly, maybe a person will use a phone app to pretend to be someone else. Maybe an IoT device will just give bad information. The cause might not even be hacking, maybe just a software bug, human error or biases caused by differences in peoples’ taste or perspective. How can all these be avoided?
The coordination problem
Also, whatever your IoT project is about, the issue is more than just about whether you can trust some device. There is also a coordination problem. The potential of an IoT ecosystem lies in the combined sensors and capabilities of many devices. For example, many cars sharing congestion information is much more valuable than the information from just two cars. So the problem is to get many devices to work appropriately with many other devices. Trust and appropriate behaviour need to be guaranteed for all the devices that work on a particular problem or service.
It all boils down to two problems. How can you trust your own devices not to be hacked and how can you trust devices that you do not control to do what they are supposed to do – in a joined-up way?
How can we be sure of the identities, past behaviours and current permissions of other people and devices? How can we coordinate many devices so that they work in a joined-up way? And how can our devices do this checking automatically?
Fortunately a similar problem has already come up with digital currencies like Bitcoin. Digital currencies also need to be trusted and they need many people to join-up in agreeing that a particular buyer owns the digital cash to be able to pay for something. Buyers want to choose from lots of sellers so all the sellers have to agree that they trust the currency – even though the amount of cash each buyer and seller owns changes each time someone buys something.
Cryptocurrencies, like Bitcoin, solve this problem by using a distributed ledger like blockchain . A distributed ledger is a database of transactions that is shared and checked across many computers. And transactions can be money transfers or they can be IoT devices sharing data with each other.
Solution: You are what you do and what you do can be recorded
Blockchain technology is much more than the foundation of Bitcoin. Transaction data can include peoples’ identities, devices’ identities or any other useful data such as how they behave. Recording transactions makes it possible to know the real identity of every device and what it has done in the past.
New transactions are cryptographically recorded into blocks and each block in the chain of blocks is cryptographically linked to the previous block to stop tampering. The data in each block is encoded and part of that code is based on the contents of the previous block. To successfully tamper with this record would mean hacking all the computers in the network simultaneously, whilst at the same time guessing how to decrypt each block and the links between them.
Blockchain technology preserves trust in three ways: multiple copies of a single blockchain are shared and continuously checked; the data in each block is encrypted and to decode one block you need to decode the preceding blocks.
So, the problem of IoT devices trusting each other could be solved by using a blockchain technology to encrypt recordings of past behaviours and current permissions. And the problem of coordinating many devices could be solved by sharing a single blockchain database across a network of devices.
Of course there are many distributed ledger technologies and many types of blockchains. My point is that technologies like blockchain solve the trust problem by continuously checking multiple copies of a database that is securely synced. And automatically synchronising multiple copies of the same database is also a strong basis for coordinating multiple devices.
Trust and coordination are two things that IoT ecosystems will badly need. So blockchain technology looks like it will be a foundation of the IoT ecosystem and much more.
Internet of Things devices work better together, the more IoT devices that link up the better. So which devices and which apps should yours connect to?

In the Internet of Things (IoT), the more devices that connect with each other then the more perspectives and capabilities there are to be shared. More data from different sensors and data suppliers; and more ways to change the real world. Like operating cars, home appliances and other machines or getting really useful options from screens or bots.
If you are a device manufacture or an app developer the problem then is: which devices and apps should yours connect to? If you can potentially link to any device and any app then which are most appropriate?
How do you avoid confusing your users when they use your product? How do you avoid confusing yourself? What to connect to is not a problem for the user. The device manufacture or the app developer needs to figure this one out. Just give users a simple list of high quality options that are personalised to their current situation.
Your product cannot link to every other device on the Internet. So which devices have the most useful perspectives and capabilities? You need a strategy that helps your product to be better at its purpose.
And don’t forget security.
Next, having chosen which other potential devices or apps should work with your product you then need to persuade their makers to partner with you. There might be an API to help you connect but close data sharing and brand associations needs discussions and agreements. And that means you need to get noticed, get taken seriously and get a mutually beneficial deal.
The prize is that the first products to build up their IoT ecosystem of partners will get more data and features to build into better services. As my son knows very well, a bigger and more varied pile of Lego bricks means he can build a more interesting spaceship or a more secretive secret base.
There is a lot of talk about business ecosystems and an ecosystem of IoT devices is a lovely thought in principle, but what actually is it and how do you build one? Looking at natural ecosystems might help us.
Natural ecosystems are glued together by ‘nutrient pathways’
The glue that binds together natural ecosystems, like rain forests, deserts and even a single puddle of water is their nutrient pathways.
What we think of as natural ecosystems are actually the ‘pathways’ that recycle scarce resources. The essence of natural ecosystems are nutrient flows along pathways which are based on the natural activities of many different organisms.
Whatever the ecosystem, the quality that makes a natural ecosystem stand out; the thing that makes people say ‘that collection of organisms and stuff is an ecosystem’ is how it moves resources around itself. Microbes, insects, larger animals and plants and other living things move resources around just by living their lives.
The animals, plants and other organisms can come and go, die off or just move to another ecosystem. The pathways need not be dependent any particular organism or even a single species. But the thing that makes an ecosystem appear to us as an ecosystem is the way it recycles scarce resources.
For example, rain forests actually have relatively few nutrients, the soils are very poor. When leaves fall to the ground they are broken up by tiny organisms. Then the nutrients are absorbed by fungi and quickly recycled back into the trees by their roots.
Recycling and reusing nutrients along specific pathways is what makes one natural ecosystem different to another. Different organisms have different ‘roles’ in the pathways and each role might be performed by several different species.
Business ecosystem pathways glue together the IoT ecosystem
If pathways that recycle scarce resources are the essence of ecosystems then what are the scarce resources that business ecosystems can recycle?
The scarcest resource for most businesses is customer knowledge. Customer knowledge about the situation any individual customer is in at the exact moment when they use your product; and knowledge about how all customers have used the product in different ways and in different situations.
Knowing the situation which an individual customer is in as they are using the product enables the product to be more responsive to the customer. And it enables the customer to get better advice and suggestions for using the product.
Learning about how all customers have used the product in different ways and in different situations helps a firm to improve the design of the product with software upgrades or with hardware redesigns. Or it helps to suggest solutions to common problems that customers find as they use the product. These solutions can even be suggested to customers by the product itself.
For example, Sat Navs make travel route suggestions and cooking apps make recipe suggestions. Knowing more about the bigger picture of the users life – the reason for the journey or the reason for the meal – would suggest more personalised options. Knowing what other users have chosen in similar situations would help generate more options as well as a more accurate link between a suggested option and a given situation.
This sort of information was scarce before devices connected to the Internet because the direct relationship with users was mainly with retailers rather than product manufacturers. Also, an Internet connection enables products to record how they are used and then to send this information back to their manufacturer.
Product usage information can be combined with information from different products and other information about users’ lives. A deep understanding of the wider situation that a product is used in helps it to be used more successfully.
The IoT technology stack is a good way of explaining how smart products can connect up and share data. But how do you build ecosystem’s pathways?
Building an IoT ecosystem by choosing devices to partner with
To start building your ecosystem, first ask ‘What customer knowledge do you need to make using your product more successful as it is used and also as you design and (re)design your Minimum Viable Product?’ Do this for every stage of your users’ journeys.
Next you need to choose the data suppliers who can share the data you need to manufacture this customer knowledge. The data suppliers who you partner with (the devices, apps and other sources) will be the components of your ecosystem pathways. The order in which they work together is the flow plan of the pathways.
And how do you persuade them to do it? Just explain to them how it all works using the logic behind your flow plan of ecosystem pathways. Your flow plan describes how each device or app plays its small part in the wider scheme of your ecosystem’s work just by doing its job.
Each device or app has a job to do, its role. So your flow plan of ecosystem pathways is also the business model of why your new ecosystem will work.
IoT devices can be anything with computing power and an Internet connection. Phones, tablets, PCs and games consoles can all be the ‘things’ in the Internet of Things. Even refrigerators, cars, washing machines and stand-alone sensors like web cams – if they have a web connection. And all the apps on your phone certainly have computing power and an Internet connection.

The ‘Internet of Things’ and the ‘Internet of Everything’ just mean collections of different devices and apps that work together with some common theme, which is usually called an ‘ecosystem’. The healthcare IoT ecosystem is the collection of all the devices that medics use on their patients. The Quantified-Self ecosystem is like the healthcare ecosystem but it is more about the devices and apps that we use ourselves, to monitor our own activity levels and our bodies.
For example, Fitbit and Jawbone gather physical activity data, Scanadu is a urine testing system that can be measured by a camera phone, Quealth assesses your risks for five major diseases, and there are many IoT sensor products.
Some early stage IoT ecosystems are themed around smart cities, which aim to use digital technologies to manage key services like food, energy, communications and transport as well as citizen participation. Smart cities need smart buildings, which are a whole ecosystem in themselves. And smart buildings are full of smaller devices that are owned by different people who do not necessarily own or live in the smart building itself.
IoT devices need to connect with each other
The key to the IoT is that the ‘things’ can connect to the Internet to help users to use them and to get better at doing so. An IoT toothbrush can use your phone as a keyboard, a touch screen and a dashboard to display how you clean your teeth every day. And it can make suggestions based on how other people do it or on the latest dental research.
Each device’s Internet connection allows it to compare how you clean your teeth with anyone else that uses a connected toothbrush. Learning from other users is a great way to make any product easier and more successful to use. The same applies to the Waze app as it crowdsources warnings of delays and snippets of journey advice. Rolls-Royce also learns from huge numbers of its engines by using sensors to track their health in real-time as they fly around the world.
Without an Internet connection each IoT device is just a device. But when lots of devices link up they potentially get access to two things – all the other devices’ perspectives and all the other devices’ capabilities.
The other devices’ perspectives are like when Wayz users share information about delays or traffic jams, as they experience them. The other devices’ capabilities are like when the purpose of one device complements the purpose of another device.
For example, your home weighing scales, the treadmill at your gym, your refrigerator and your supermarket shopping app could all share information with a cooking app on your phone. The cooking app could then suggest meal recipes based on your weight, your exercise levels, what you have in your refrigerator and the ingredients will be delivered that evening.
The scales, the treadmill, the refrigerator and the two app have different perspectives on your life, their sensors ‘see’ different things. These devices and apps also have different capabilities to do different things for you. Like ordering ingredients or making recipe suggestions.
Even a passive device like your home weighing scales can make useful suggestions, if it knows more about your life than just your weight.
The success of an IoT ecosystem is based on the ‘network effect’.
The ‘network effect’ is the idea that the more members in a network there are then the more valuable it is to be a member of that network. The opposite of this idea is like when a new social network has very few members.
In the IoT, the more devices that connect with each other than the more perspectives and capabilities there are to potentially be shared.
But the challenge for ecosystem builders is to figure out which devices to link together into an ecosystem. And not just devices. Apps, firms, government departments, public services and consumers are all potential members of the Internet of Everything. You cannot link and share with every single one, so how do you choose?
One way to choose is to focus on a theme – health, travel, a sport or a particular job role. But there are still many firms to partner with and many sources of data to potentially access.
In the next post I’ll explain how to choose partners and devices to build an ecosystem from and how to persuade them. I’ll take some ideas from natural ecosystems and use them to show you how to build your own IoT ecosystem around your device, app or business.
I’ve a new post on Econsultancy, the digital marketing blog. It’s from some research I’ve just done with Maybe*: How do millennial shoppers decide what to buy?
We’ve shone a light into the dark recesses of the customer journey. The earlier on along the shopper journey you go then the less you know. But earlier on is when you want to influence shoppers. You can read it here.
Control Shift, the personal data experts, asked me to do a blog on TACKLING THE DATA SHARING CHALLENGE.
There are many benefits to sharing more data between firms and other organisations but right now, as a society, we do not know how to do it safely. In the blog I look at some of the opportunities and pitfalls, then I suggest a way forward.
I contributed comments to the recent Information Commissioner’s Office report on Big Data and Data Protection.
UPDATE: The above link is the ICO’s new report which includes Artificial Intelligence. The older report with my contribution is here: big-data-and-data-protection.
Personal data can be used for great harm as well as for great good. The more that data is shared between organisations then the more value it can create.
But personal privacy is becoming more and more of an issue, although the way firms handle, share and reuse data is much too complicated for most individuals to be fully aware of or able to deal with if data is mishandled.
For the last year I’ve been running roundtables, interviewing experts and going to workshops to try to look for some answers to these problems. This white paper explains some findings so far.
Personal Big Data: Is there a missing third party in our emerging Big Data society?
Executive summary
New Big Data technologies are rapidly changing marketing, healthcare, government, financial services, retailers and whole supply chains.
We are rushing towards a ‘Big Data society’ that is using data analytics to more efficiently target resources and to deliver incredibly personalised user experiences. But the precise use of resources and the personalised delivery of services require access to deeply personal consumer data.
Personal data can be used for great harm as well as for great good. The more that data is shared between organisations then the more value it can create – and the more difficult it is to control who uses it and what they use it for.
The change in how organisations use our personal data is happening whether we like it or not and we risk destroying trust if consumers are harmed or even surprised, by how their personal data is used. We need consumers to trust how their data is used or they will be slower to engage by sharing their data. This will delay the benefits of a Big Data society and leave the UK to be potentially overtaken by other countries with a different view of the importance of consumer trust.
But current systems of legislation and regulation are based on older technologies and ways of working that did not include cheap access to mass data sharing capabilities and personalised data analysis in real-time.
Our investigation incorporates the views of experts from regulators, government, commercial data firms and consumer privacy organisations. It concludes that there are several missing roles in our emerging Big Data society – a missing ‘Third Party’.
This ‘Third Party’ would support individual consumers to deal with networks of large and small firms; help firms to share and use data in new ways in return for doing so appropriately; aid regulators to bridge the gap between the market and individual consumers, staff and firms; and give privacy and consumer organisations a platform to help more consumers and to engage with more firms.
We propose a solution, a design for a ‘Third Party’ that engages the attention and resources of the different stakeholders to watch and help each other. Firms would have a strong interest in behaving appropriately; and in turn they would encourage their staff to behave appropriately and become more successful in the process.
Here is the full white paper: Personal Big Data white paper 3.0.
Reform asked me for a short piece on some of the implications of sharing data and mobile phone data – Our society needs to learn how to share personal data safely or we will all lose out.
I did a new post on Econsultancy, the digital marketing blog. It’s about the opportunities and dangers of sharing customer data.
Sharing lets us use our resources much more precisely and produce completely new services. But misusing customer data risks destroying customer trust.
Still, we all need that missing piece of the Big Data puzzle, so we all need to share more. You can read it here.

[Source Wikimedia Commons]
Big Data is changing how organisations make decisions, who makes the decisions and even the types of decisions to be made. If we think of organisations in terms of decision-making structures and processes of decision-making then what will these look like in an organisation that fully uses Big Data analytics?
Some people are well past the ‘bigness’ and IT focus of the Big Data conservation and onto the Analytical Strategy (e.g. McKinsey or Booze & Co). But I haven’t seen much about how decision-making in organisations will change and how this will change organisational structures and activities.
But the issue of how Big data Analytics changes decision-making has cropped up recently in my dealing with several organisations and it could completely change in the next few years. Here I’ll explore some of the options and possibilities for organisations and their decision-makers.
Centralised versus decentralised decision-making
Lots of firms with huge numbers of staff in different locations have a highly centralised way of making decisions. Take the major retailers. Most of them have moved to a highly centralised ordering policy – so centralised that store managers are not in charge of ordering stock for their own store. Store managers handle staff and service but they can only indirectly influence the orders that are delivered to their store.
I once asked senior managers from one major UK retailer if it would be a good idea to give some decision-making powers back to store managers. The reaction was shock, a waving of hands and shouts of ‘it will be chaos!’.
But some decisions are handled locally, like staff-related issues. I’m just wondering which other decisions would be better handled locally, in a way that reflects local conditions. Decisions that help a store to better fit the needs of its local area or the events that happen that day or that hour.
For example, weather can be very local. Different local weather conditions can lead to very different local needs for different stores in the same retail chain. Events happen differently in different towns and urban areas – not all fairs, celebrations, processions and markets happen on the same day. Different local churches, schools, Scouting and other organisations hold events when it suits them. Different places have very diverse histories and customs and we all know the local customers vary – just look at Experian’s Mosaic.
Personalising a store for it’s village
The best way to satisfy a customer’s service-needs is by personalising your service. What I’m talking about here is personalising a store for it’s village, town or urban area.
So how do you let local staff make more decisions to without causing chaos? Answer: keep the decision-making framework centralised – you own it, you control it – and let the staff make their decisions within that structure.
Levels of self-service
If you want to design a decision-making framework where the framework itself is centralised and global but where the decisions themselves are made locally then a good place to start is with the decisions that customers make.
One way to model the customer journey is as a decision-making process. If you can help customers to understand the decisions that they need to make, help them get the information that they need to make those decisions and help them progress along their personal decision-making process then you will make it easier for them to buy from you or buy from you again. This is the objective of lots of content marketing .
Automated services are increasingly being used to ease customers along their personal decision-making processes by helping them make the decisions that they need to make, e.g. Goole Now.
In different industries mobile apps or web sites provide automated analytical services to customers in the form of self-service functions help them as they decide to buy and then as they use firms’ core products and services.
For example, recent regulatory changes to how financial products are sold in the UK have meant that the cost of financial advice is now not included in the cost of the product. This summer we are running a research project to investigate the advice and decision-support requirements that lower income customers have when considering certain financial products.
We hope to understand how to provide low cost, standardised or automated support to fill the advice gap that is felt by customers that are too poor to easily shoulder the burden of bespoke financial advice but with personal financial requirements that are too complex for basic products.
Higher levels of self-service
But self-service is increasingly being used within and between organisations. It is now common for people to be able to update or check their own HR and financial details just by logging in to the corporate intranet. Jobs that would have been done in the past by HR or finance staff.
Self-service is also becoming a way of putting decisions in the hands of the person who is best able to make them. The person at the right place, at the right time or just with a personal understanding of the context of the decisions that need to be made.
The integration of multiple organisational databases, and APIs from outside the organisation, has led to much more data being available and now Big Data analytics is increasingly being used to produce self-services.
Big Data analytics can be used to produce self-services for staff as well as customers. These are based on centralised decision-making frameworks that reflect the global needs of the organisation whilst preserving local flexibility.
If you want to design such a decision-making framework, i.e. a strategy for how your organisation makes decisions that fit global as well as local needs, then think about how you would design self-service decision-making tools for customers and the rest of your staff at different levels.
How can you help customers progress along the decision-making journey of their lives? How can you help your staff progress along the decision-making journey of their job roles?
Decision-making journeys and Big Data visualisation
Here’s a clue: it’s part of the on-going conversation about Big Data visualisation. Some analytical outputs cannot be represented in a pie chart. Some need a 3D graph, some can only be conveyed in a video, some can only be usefully explained in an interactive simulation.
If you want to support (or constrain) people in the decisions that they are making then you need to present then with enough information to make that decision. Too much information and you get information overload. Too little and they will make biased or less useful choices.
Practically speaking, there is no ‘optimal amount’ of information but the human brain can only fit so much in at once. So the objective becomes getting the most out of a brain’s capacity and this depends very much on the way that the information is conveyed, presented or visualised.
The reason why visualisation is developing into a major subset of the Big Data bandwagon is that it (a) the decision-maker is usually not an analyst or a data scientist and (b) visualisation itself is a product of many previous decisions about what information to pass on and how to portray it – filtering decisions and combining decisions.
In other words visualisation is also decision-making. Deciding how to visualise analytical outputs is just as much a part of the decision-making process as the ‘final’ decision that whoever looks at the visualisation makes.
So if you are designing a decision-making framework think then you should about it as an organisational process that starts centrally and globally, in a standard and stable manner, and then moves towards the edges of the organisation where it can be finalised in a varied and agile manner in many different instances.
Think about your decision-making framework as a self-service environment that connects all the people in the business process in question, including the customer and the suppliers.
The benefits of global + local decision-making
Here’s a few:
New research project – get involved
Not many firms are thinking about how Big Data will affect their organisational decision-making. So it would be interesting to talk to senior people in HR, business transformation about this or a more Big Data analytics oriented department. We are starting a new research project to look at the organisational design implications of decision-making that is supported by Big Data analytics. Possible research questions include:
1 Which types of staff roles will start to use Big Data analytics technologies, e.g. simulation sandboxes to do low cost, low risk, quick checks of hunches?
2 Which types of decisions will move between roles, up/down, across functions, e.g. nearer to the person who understands the context of the decision or nearer to the enactment of the decision outcome?
3 Which types of decisions will become more data-driven, either real-time, not real-time or on what timescale?
If you want to talk about this subject then please contact me at duncanshaw_1@hotmail.com.
I recently did a post about Google Now on Econsultancy, the digital marketing blog. It’s about how Google Now is a great new service with its near psychic ability to make inferred suggestions.
But the real story is in how it gives Google a much much wider window onto users’ data than Search ever did. You can read it here.
I’ll be speaking about what Big Data can do for marketers at Marketing Week Live on Wednesday.
We’re starting Big Data discovery projects with several firms right now to see how they can really sweat their data assets – so come along for some new ideas and a chat.
I’ll be in DD4 from 12.45 to 13.15.
Big data research partners wanted.
We are developing completely new ways to look for patterns in data. Our data scientists uncover patterns. Then we show you which of these patterns are most useful and how to use them to better meet your organisational objectives – and to get better objectives.
From data provenance to analytical discovery, data-led service development and product improvement, high-granularity marketing and sales strategies, big data supply chain and operations strategies, planning additionality and measuring ROI.
We can help you to use Big Data techniques in all the functions of your organisation. You can make strategic decisions, harness your creativity and business experience, monitor and manage operations and do business like no one has ever done before in your sector – because we are focused on discovering entirely new analytical techniques and the analytical strategies for generating value from them.
Typical project components
We combine the absolute newest research in Data Science with an intimate understanding of how your business model creates value. Data science uncovers new patterns in your organisational data, our analytical strategies fit them to your business context.
We are working with retailers, marketers, data firms and customer loyalty firms – we want to work with all business sectors and the public sector.
We are signing NDAs right now and there are a few places left on the first round of Analytics Discovery projects.
Use our ground-breaking academic research
Research projects normally start with a mutual NDA and we are more than happy to help you develop marketing content that takes advantage of your participation in developing state of the art business analytics hand-in-hand with ground-breaking academic research.
Get in touch to do something your competitors have never even heard of yet: duncan.shaw@nottingham.ac.uk.
If you’ve got the time then join me for a live chat from 1-3pm on the relationship between marketing and Big Data – here
Econsultancy just published a really useful free report: Big Data Trends Briefing: Key takeaways from Digital Cream London 2013.They were kind enough to include a few quotes from me but the reason I like it even more than that is the huge number of examples, case studies and other resources that it highlights. It’s a really useful gateway to all things Big Data: the main issues, opportunities, barriers and potential solutions.
Big data analytics is inherently ‘multilevel’ – it’s not just about very big, company-wide issues; or about very personalised and immediate consumer issues. It’s about both of these and every level in between.
Making it work at every level of the organisation, and in real-time, is now possible. One size fits all is no longer mandatory and as a result much greater efficiencies can be gained. This is an example of ‘good complexity’ – using an data analytics strategy that personalises customer experiences and staff insight and information requirements at every level.
But Big Data’s scale means that it crosses organisational silos, you can see this in the fragmentation issues that have been thrown up already. The upshot is that the sponsorship for Big data projects needs to be much higher up, i.e. a board-level sponsor for board-level issues.
Which means that you need to talk about board-level benefits when you argue the business case, e.g. a commercial director of a big ecommerce site recently told me that he was really interested in increasing Stock Turn (i.e. greater overall sales volume with the same working capital).
That got me thinking about analysing sales data to highlight products with characteristics that impact Stock Turn (sales value, velocity), then checking for the specific customers who buy them or would buy them and then influencing those customers using direct marketing like texts and email. Marketers in different digital areas do this stuff all the time but I haven’t seen it linked to how to influence specific Board members.
Big Data is now moving towards being more about analytics and Organisational Change, i.e. there’s no point in deciding what to do next if you can’t then do it.
This is what we are researching right now:
We’re looking for research partners so if you want to have your Big data itch scratched and get the benefits of a few of the opportunities that I blog about then let me know: duncan.shaw@nottingham.ac.uk.

Source: Wikimedia commons
In the last few weeks I’ve been to three roundtables that were full of experts on Big Data and Big Data analytics or business users of the insights from such analytics. There were also a few Members of Parliament and senior industry regulators.
The first roundtable was at Econsultancy, the second was at the think tank Reform and the third was a Personal Big Data roundtable. These round tables addressed three very different aspects of Big Data but there are some common threads that stretched through all of them.
The first common thread was the richness and variety of the topics that we discussed. Big Data is a new and emerging set of technologies and right now we are at Big Data 1.0 not Big Data 2.0. The discussion at these roundtables, just like Big Data articles on the web, was as unstructured as Big Data is itself. When a structure forms we will call it Big Data 2.0.
Some people were focused on the hardware, some liked to talk about the data it handles. There was a huge amount of discussion about ‘data’ and less about what data or which data. Indeed there was a general thirst for examples, case studies and illustrations of uses of Big Data.
There were also lots and lots of metaphors like ‘Data is the new oil’ or my own biased favourite ‘Big Data is like the minute-to-minute personal diary of everyone and everything’. When it is unclear what ‘something’ is, a something that is emerging as we develop how we use a these technologies, then metaphors are very useful. They help use to generate potential forms that we can check and test for usefulness.
Even the experts have different points of view and many questions about what form, or forms, Big Data will take. However, there are a few rough characteristics starting to take shape and this is what I hope to describe here.
The second thread that ran through these roundtables was that there was more talk of the hardware and the data themselves rather than of the actual services that Big Data analytics could create.
It is relatively easy to deconstruct a service after it has proved highly popular. But thinking up that highly popular service in the first place is very hard. Right now we have some new hardware, access to vast amounts of raw material data and a complicated range of analytical tools but it is unclear how to combine all these into specific configurations that produce the ‘killer apps’.
One way around this might be to start out with some commonly valued objectives and work backwards to try and connect them to the outputs that we know that our new analytical techniques can produce.
For example, both government and industry are perennially keen to [1] increase services or sales, and [2] make savings. And we know that a key role of these emerging analytical techniques is to help us accurately understand the needs of people – on a more personal and individual basis.
So we should be looking for analytical techniques that suggest the unmet needs of citizens and customers – because knowing unmet needs helps us to increase services or sales. And more precisely tailoring the services that we already provide could reduce wasted resources and make savings.
These analytical techniques are based on analysing the individual interest graphs and contexts of peoples’ lives, e.g. here, and they are the foundation of Big Data services.
The third thread was about balancing the societal and individual privacy aspects of Big Data. Economic growth from new Big Data firms and services depends on consumer trust. But these services depend on organisations sharing consumers’ data between themselves.
Few organisations share enough of a person’s life to understand their needs very deeply. But sharing data for good or for profit generates questions like How do I control my data? How do I share in the value that it is used to create? and How do I fix it when my data is hacked or stolen?
The Personal Big Data roundtable in March brought together some of the leading experts in data analytics, retail, healthcare, financial services and some key industry regulators. These questions were at the top of our agenda but they were also touched on in the other two roundtables.
The point is this: consumer trust depends on regulation, which depends on legislation, which in turn depends on policy. But current regulation, legislation and policy are inadequate for handling the opportunities and dangers that Big Data presents society – they are not so much out of date, it is more that they have been made technologically irrelevant.
From my research I am starting to see how the regulation and legislation could be developed in order to support the societal benefits that we hope to gain. To do this we need to help legislators and regulators to start this change process – stories and case studies will help but there are no case studies for some of the more complicated inter-relationships and business models that are yet to emerge.
The forth thread concerned the people, citizens and customers, that we are describing increasingly accurately with these new technologies. People do not only vary in terms of their needs for different services, which is why we analyse their data. They also vary in their attitudes to privacy – people exist on a spectrum of sensitivity with some not caring about data privacy and some being highly sensitive.
Also, people rarely read through user agreements – they do not have the time nor the training, e.g. when they download an app that will give the app firm access to the content of their mobile phone and their location on a 24 hour a day real-time basis.
But most interestingly of all, when you spend a lot of time surrounded by experts, it is worth noting that most people lack an awareness of just how the technologies that I talk about here are changing their personal and work lives right now. There is a huge need for education and awareness if people are to get the most out of these new services and use them safely.
There are two main implications from the discussions that I have had the pleasure of being part of in the last few weeks.
The first is that there seems to be some vacant niches in the Big Data ecosystem, to use another metaphor. There are some unfilled roles, like a broker that would manage a person’s data and deal with firms on their behalf; a defender of a person against harm; a fixer of such harm; an educator that teaches people what they need to know about our unfolding Big Data society; a new form of regulator to uphold public interest; or even a third party ‘dating agency’ for firms and their data.
These roles might not exist within the same organisation. Indeed some of these roles may be taken up by regulators or they may fall to multiple competing Third Parties rather than a single organisation.
The second implication is that there is a huge and complex gap between the raw material Big Data, on the one hand, and the consumer needs that it could be used to satisfy on the other. We know that we have lots of data and we know that we can buy-in, swap or access more data. We know that we have some sexy, fast, new hardware and unbelievably clever analytical software. We even know that we want to hit the same old organisational targets of doing more with less.
But we do not know which particular data to use; which particular software to install and learn to use; which specific way of using the software, which analytical services to produce out of all those that we could; which consumer needs to target, even which consumers to target. The huge and complex gap is made up of all the dependencies in the last sentence and we are only now starting to come up with Analytical Strategies that can bridge it.

[Source: Wikimedia Commons]
Retail is being drastically changed by new digital technologies like Big Data analytics and the services that mobile smart phones can deliver. Big Data has been discussed a lot but there is little analysis on what it can specifically do for firms and their customers.
Also, apps that run on Mobile devices, like smart phones and tablets are revolutionizing multi-channel retailing and customer relationship management. But mobile apps are usually just catalogues and directories when they could be personal shopping ‘sat navs’ – like your best friend owned the store.
Most pressingly of all, there is very little useful thinking, or practical advice, available on the overlap between Big Data analytics and personalised services that are delivered by your phone, i.e. the links between the outputs of very large scale analytics and the very small scale personal needs of individuals.
Firms are still working out what they can do with these technologies. Customers are still deciding how they want to use them.
We need a roadmap
New digital technologies are producing a bewildering number of options: new shopping and customer relationship technologies, new Big Data information resources, new analytical possibilities and new business strategies.
Firms need an underlying roadmap for taking advantage of these new tools and resources as they unfold and develop. We need to connect back to the fundamental business objectives of commercial success and amazing customer service in the face of a chaotic digital landscape.
This is the first of three linked posts that show the significance of these technology-driven changes; explain the underlying processes at work; point out the business challenges on the horizon; and map out the strategic options that are now possible for retailers, their customers and the brands that they partner with.
Part One covers how new Big Data and mobile technologies are changing marketing, retail and the rest of business from a business strategy perspective rather than from a technological perspective.
Part Two maps out and explains the confusing new options and approaches that these new digital technologies are now making possible. From the retailer’s perspective, from the customer’s perspective and from a business strategy perspective.
Part Three explains some ideas on how to deal with the emerging possibilities described in the first two parts – from a strategic and analytical perspective, then from an implementation perspective and then with a consideration of how these fascinating changes will continue to unfold.
Part One: A mobile app is like the finger of God
Mobile apps are location-here, segment-of-one, stage-of-now, and downloaded by YOU.
Every app can potentially give you incredibly personalised recommendations, suggestions and advice based on knowing where you are, who you are, being with you every minute of the day and being trusted by you (you downloaded it).
These dimensions are revolutionising how firms communicate with you, learn about you and produce services for you. Everyone you know and most people that you don’t know also has a phone so you could multiply the previous sentence’s possibilities by most of the human population.
But neither firms nor consumers have fully worked out how to use these dimensions. Using mobile phones to figure out a person’s location has grabbed a lot of headlines and initiated a few start-ups and service features like geofencing.
Services that run on smart phones naturally segment customer populations down to a single individual because we rarely share our phones. So phones are platforms for personalisation, i.e. precise learning about individual needs as well as giving customised advice and information.
Also, we carry our phones around everywhere and a lot of people never switch them off – so services can potentially be real-time and anytime, whenever customers need them. Most importantly of all, customers choose to download the app and then give the app the permissions it needs to work.
So services that are delivered by phone apps [or mobile sites] have the capability for complete personalisation in terms of ‘where’, ‘who’ and ‘when’ plus they are a potential bridge for two-way exchange of information.
What goes around comes around
Complete ‘who’, ‘when’ and ‘where’ personalisation is great but an app [and the huge supply chain behind it] needs to know which service options, product variants, SKU number, model, user experience configuration or other permutation of what it could potentially provide is best for each particular ‘who’, ‘when’ and ‘where’ customer at the moment that they tap the screen to say they want it.
This need to decide which service would best fit the immediate needs of a specific consumer will be even more pressing when apps suggests useful things without an actual request from the consumer. Like Google Now is starting to do.
The absolute best thing about mobile phone apps and services is not their in-build sense of ‘who’, ‘when’ and ‘where’ – it’s the information that the consumer gives to the app owner or service provider [and the huge supply chain behind it] plus the permissions to use it.
Mobile apps are not just a bridge to God-like services – they are a two-way bridge to God-like services.
‘God-like’ means not quite omniscient, i.e. you have to give the app some clues as to what you need from it. Mobile apps know who you are [you registered], when you ask for something or contextually might need something [they are always on] and where you are [they are in your pocket]. So if the app does not abuse the data permissions that you give it [an unresolved issue] and keeps being indispensible then it can potentially act as the ultimate loyalty card.
Introducing the ultimate loyalty card – the Mobile + Big Data version
Big Data is the minute-to-minute personal diary of everyone and everything. Mobile apps have the potential to be the pen that writes your Big Data diary.
All our on-line transactions, communications and surfings are recorded and increasingly stored, analysed and used. But there are still vast gaps in our personal Big Data diaries. For example, a huge retailer like Tesco with a tremendously sophisticated loyalty programme, like Clubcard, only directly knows about the part of your life that is your shopping-life. It can buy-in shared data from its partners to get a better insight into your specific needs. But it can never know your full Big Data diary.
But a mobile app [or collection of apps and mobile services] – that you trust enough to give the right permissions to about collecting your personal data and that you interact with as you go through your life events – could potentially know your whole Big Data diary. The Big Data diary of your on-going minute-to-minute life.
Just think of how helpful [or dangerous] this could be. Just think of the services, new services and benefits to society that this could be the platform for. Nobody could accuse those people behind Siri and Google Now of aiming too low.
Linking smart phones and Big Data means everything in the cloud delivered to you, right here and now. The intimacy, immediacy and relevance of smart phone apps is combining with the vast scale and power of Big Data and the cloud.
This generates many confusing and unfolding possibilities. A massive aggregation of information and other resources is combining with a highly specific understanding of customised requirements. Very large scale Business Intelligence is colliding with very small scale human needs.
The scale and variety of Mobile Big Data is both an enabler and a barrier. For firms and government it changes the problem from ‘we would like to do’ to ‘which should we do?’ plus ‘are we sure that’s the best thing we could do?’ There are too many new possibilities in too many new areas.
Part Two maps out and explains the confusing new options and approaches that Mobile + Big Data is now making possible. It does this from the retailer’s perspective, from the customer’s perspective and from a business strategy perspective.

As firms scale up the use of information in business using Big Data analytics there is an increasing interest in measuring the value of the data. Not just the ROI of the projects that use it, but the asset value of the data itself.
Pete Swabey recently wrote an article in Information Age about the connection between the value of a firm’s data assets and the market value of that firm. He highlighted how most firms do not formally measure the value of their data assets so their data’s value is not included in their market value. Commonly, they do not treat their data assets appropriately, and even more worryingly according to his article, their insurers do not recognise the value of their data assets.
However, measuring the value of data is easier said than done because valuation is ‘in the eye of the beholder’, i.e. value is personal and individual. Value is also dynamic because it is affected by personal experience and events, and it depends on personal context, i.e. the user’s past history and future goals. So valuation of a resource depends on a fit between the resource and each individual user’s ever changing personal needs.
Value is not some frozen and unchanging characteristic, it is ‘value-in-use’ and the value of data depends what you use it for – which makes things even more complicated because you can use and reuse your data assets many times without wearing them out. (Maybe you only ‘wear out’ data when you tell someone something that they already know).
Swabey’s article describes a few useful ways to start to calculate the value of your information assets but measuring value of your data is not straight forward when there are so many unexplored uses for it.
A solution to this problem needs to start with an understanding of how your data could be used and the individuals that could use it. I.e. start by mapping out all your uses of your data (by staff role and function); then do the same for your current business partners (since you are in the same supply chain or ecosystem); then think about opening it up even more.
Sounds risky? Well yes, there needs to be a set of safe guards and frameworks of use. Look what happened to Tom Tom when it shared its data.
But if the value of data is only really apparent when it is used, and its uses are mostly unknown, then the best way to explore this problem is to ask potential users for ideas, i.e. to open source it.
Conclusion
Opening your data up to new users and infomediaries would let you access new ideas for using it. And the value (and risks) of each new idea could then be assessed. This way also brings in highly engaged customers and partners for services that are based on your data assets.
Are you feeling guilty about not using your Big Data enough? You know that you have loads of it and that you should be making the best use of it. But maybe you don’t know how to monetise it by turning it into new services? Or maybe you suspect that there are additional ways to ‘sweat’ your data assets?
The problem is that great services are obvious after someone has thought them up and implemented them. But there are an infinite number of ways to analyse and process your own data and combine it with bought-in data. So choosing which one to use is almost impossible.
Of course, you could look at what your competitors are doing. But its early days for them as well and they may be keeping it rather secret.
Its better to start with unfulfilled needs and then work backwards. You could look to your customers for inspiration. Trace the path of their user experience throughout the whole sales cycle – maybe there is some missing service that you can use your data to produce. Another benefit of this is that it keeps you focused on where your revenues come from.
But what about other uses for the data that you and your supply chain produces just by functioning? Data is not necessarily a consumable resource. It can be used and reused forever. And each time you use it, you generate more data.
If you have the feeling that you could be ‘sweating’ your data assets more but either you can’t think of new services to turn it into (or you do not want to reduce your focus on your core customers) then why not ‘recycle it’.
I call this the Steptoe & Son method – in the US you would say ‘Sanford and Son’ – after the famous TV characters that collected old products that were no longer useful to their owners and then they reconditioned and reused them.
Big Data is like the minute-to-minute personal diary of everyone and everything. There are too many possible uses for a firm to implement and most do not directly support your firm’s business objectives – even if you could think of them all.
But maybe other firms could use some of your data? Maybe firms with an underlying link to your supply chain or to your customers – firms that are your upstream suppliers or downstream customers or firms that also supply to your end users.
If there is such a link between your firm and their firm then there will be a population of B2B or B2C customers that experience your services as well as their services as part of a bundle of services that these customers consume. And as with any service bundle, there are opportunities to provide new add-on services for some customer segments. Add-on services that amplify the value of the whole service bundle rather than any single component service.
One example is the location data that is a bi-product of using a car’s sat nav. Dutch police reportedly used aggregated sat nav data from TomTom to optimise where they placed speed trap cameras. This shows how the data that is generated as a bi-product of one process, car journeys, is very useful to organisations that are also concerned with that same process.
This example also illustrates another issue – the service that the reused data is used to produce for a third party may not be agreeable to the original customers who generated the data. In this example TomTom’s CEO, Harold Goddijn, had to use a YouTube video to publicly state that TomTom would stop this happening in future. Incidentally, the video also contained some other examples of third party use of aggregated sat nav data.
However, if the proper care is taken then there are ways to deal with issues like control, privacy and sharing out the new value that reuse generates. Certainly data sharing and reuse creates more value and financial services clubs have done it for years.
So, if you are interest in working your data assets harder, by ‘recycling’ them, then please get in touch.
 Think about how Tesco Clubcard and many other firms are finding out more and more of our needs, interests and other personal data – in fact every time we use a phone or a web browser to make a transaction or to communicate with friends we generate data that firms collect and can then analyse. These are the firms that we buy things from or that we ask for information to help us buy things. Or they are the firms whose services help us in other ways.
Think about how Tesco Clubcard and many other firms are finding out more and more of our needs, interests and other personal data – in fact every time we use a phone or a web browser to make a transaction or to communicate with friends we generate data that firms collect and can then analyse. These are the firms that we buy things from or that we ask for information to help us buy things. Or they are the firms whose services help us in other ways.
Whatever you do online generates data – when you search, when you click through web sites, when you register for information or when you ask questions you are generating data for those firms that are able to see what you are doing. Your broadband supplier, your web browser supplier and the owners of the web sites that you visit all know what you do because it is their service that helps you do it.
Firms can also get very detailed location information and timing information – especially when you use your phone for browsing or on the web. And that’s great when they use it for suggesting really useful things that you would never have thought of – like Amazon’s ‘People who bought these books also bought these’.
But what happens when firms lose your data or when they get hacked? (And many will) So how can you be protected? What happens when you say ‘its my data, I want to control how it is used!’ And what about sharing the value that this data generates with the person it is about, i.e. me?
So, on one side of the coin there’s the increasingly detailed personal information (Interests, Location, Time) that firms can use to help people a lot and create immense value. But on the other side of the coin there are unresolved issues of control, share of value and fixing damage when its lost or stolen. This general lack of clarity about control, value and fixing damage also means that the role of the regulators is also unclear because these issues are what the regulators’ roles are based on.
I think I have a solution to most of the problem of fixing damage, and the control problem, but I’d be interested to hear of any ideas that help with the share of value problem. I know how to create it, read my blog posts, but sharing value is different.
For example, what if I buy tomatoes from Sainsbury’s and then Sainsbury’s sells data on my buying behaviour to its tomato supplier so as to help it produce ‘better’ tomatoes. Then what if the tomato supplier makes more profit from ‘better’ tomatoes, e.g. because they are more popular. Sainsbury’s might have a clever deal to get part of that value. Like a reduced price on he supplied tomatoes or a percentage of the tomato supplier’s increase in profit.
But how can I get part of that increased profit? Should I get part?
I’m looking for different ways to look at this issue and for some underlying logic to work out how to share the value that is created. Any suggestions?
Any single retailer gets a very limited view of its customers’ lives – just the part of their lives that it helps them with. But deep insights need to be based on very broad views of customers’ personal contexts, which are understood by looking at lots of different aspects of their lives.
The social data that one firm generates by its own interactions with customers can be massively enriched by using data intermediaries that are gateways to other firm’s social data.
Let me explain. If you want to make relevant suggestions to your customers then you need to personalise your suggestions. But personalisation requires a deep knowledge of the personal context your customers.
Unfortunately, what you know about your customers is limited by what your relationship with them is about. Each aspect of your relationship is like a telescope that observes from only one angle. You can buy-in data but it needs to be linked to your actual customers which is hard for third parties to do. Also data from customers’ relationships with other firms will rarely be focusing on the precise things that interest you. It might also be aggregated or anonymized. For example, consumer classification services, like Mosaic, are really useful for getting a general profile of the people. But they cannot tell you what a specific customer is like. They enable you to take a bet with good odds, but it is still a bet.
So how can a firm with a limited view of their customers lives really understand them enough to make on target and relevant suggestions that are more than just repeat purchases? I’m talking about cross-selling and selling for different uses of their products. For financial services firms the relationship data that they generate is like looking at their customer lives through a key hole. So how can they learn enough about a specific customer to suggest different products or to suggest different uses for the same products? For example, how can an insurance firm know when a specific car insurance customer also needs pet insurance or even when they want to buy a new pet?
The answer is not scale, i.e. huge customer populations. Learning about your customers’ lives through their grocery buying habits has the same fundamental limits for Tesco as it has for a medium sized grocer. Tesco gets to learn a bit more because of the range of its offer – you cannot understand how a customer feels about electronic goods and music unless you sell a wide enough range for them to tell you their interests by what they buy and how they do so.
Customer buying data is like the tests that you go to the doctor for – they only answer the questions that you ask. If you want to check for a specific disease then you need to do that particular test. If you want to know a customer’s taste in music then you need to stock a detailed enough range of DVDs so that they can tell you what they like by buying specific DVDs. The granularity of the question enables the granularity of the answer, not the other way around.
The diversity of the different services that you provide for customers, and what you talk about with them, drives what you can learn from them. The more of their lives that you take part in then the more of their lives you can help them with – in terms of information, services and products.
One great way to get highly specific and up-to-date insights is to use social data. Social data can help with assessing sentiment, targeting communications, product and service innovation, identifying influencers and detractors, dealing with complaints and many other ways to support your marketing strategies.
Social data can be used on an individual level to communicate with specific customers. And even better, it can be used in a bottom-up way to build groups or segments to interact with at higher and higher levels. This bottom-up method is the complimentary but opposite way to segmenting top-down from you total customer population.
Best of all you can take individual level social interactions, analyse them on a segment level and then take action back down on an individual level with the personalised manifestations of a segment-level strategy.
But you only get into deep and meaningful conversations about specific subjects and specific products. Usually this means your own products, and usually it is either some way down the buying funnel or after purchase. So what you can figure out about a customer still depends on your own product range.
Which is why social data needs intermediaries – firms that help other firms to collect and most importantly of all to share social data. With the proper permissions and safeguards, of course.
Social data intermediaries can help firms to get many more observation angles on their customers’ lives. They are a way of sharing the perspectives that have been gleaned from more than one product range, which means from more than one customer relationship, i.e. from more than one angle of observing each customer.
Of course, for several brands to share data in this way there needs to be things like methods of introduction, frameworks for generating trust, ways of enforcing good behaviour, and platforms for orchestrating efficient collaboration. But intermediaries are good at these as well. And there are plenty of precedents in older areas of analytics – like the data sharing clubs that Experian and Equifax host to help manage risk for member firms.
New Analytic Strategies: lots of new toys plus Big Data – what to do now?
The key objectives of Retail remain the same. Measures like recency, frequency and value are what defines the profitability of the different retail ‘entities’ such as SKUs, lines, ranges, single stores, regions, chains, brands, campaigns, seasons, segments, channel and even individual customers.
But the increasing availability of Big Data information resources makes it hard to figure out what to analyse for and how to go about doing so. The many new shopping technologies and new supply chain technologies mean that there are too many new data sources and associated methods of using them to make it a simple choice.
The business outcomes are the same. But how can you connect these outcomes to the appropriate analytics approach, and the analytics approach to the vast choice of data that could be used?
This problem is related to part of the fragmentation problem below. When I work with retailers on customer data projects a really common barrier is fragmentation of data sources and multiple versions of the truth. I think that’s what’s behind some of the issues in Econsultancy’s report on what is holding back social marketing.
But I don’t get it. OK, there are lots of sources of data, internal and bought-in, but they are mostly known and its not a new problem so there are lots of IT integration platforms.
So what’s the problem? I think its because some firms do not really understand what the actually use of the data is – i.e. its not well specified. Then the integration (in all senses of the word) problem becomes a moving target. Which makes the problem complex.
You cannot take data at face value. Before you can use it you need to know its context – its history, provenance and the circumstances of how it was generated. You need to have permission. But permission depends increasingly on what you want to use it for and there are so many different things that a single piece of data can be used for. Right now and in the future.
The challenge is not a technical issue. It’s a matter of knowing what data you actually need and have, what analytical approaches are available to you and what strategic questions you can ask. The pattern of data, analytical processes and strategic questions can be configured in so many different ways that it makes it hard to choose. It also makes it hard to know you have made a good enough choice.
Its like the ‘chicken and the egg’ question – which came first? If you have this data what analytical process can you feed it into and what will this tell you? Or, starting at the other end, if you have these strategic questions then what analytical process will give you an answer and what data will that require?
I think the problem is about getting to grips with choosing New Analytic Strategies. A lot of confusion is caused by too many new analytical approaches that can now be used to deliver the usual business objectives. It can be unclear which approach to use and what data to feed into it.
Solution: as with all complexity problems its always best to start with the outcomes that you want and then work backwards. Working backwards damps down unmanageably large numbers of options. Here, it can systematically map out the flows of cash, transactions, customer decisions, queries, attention and awareness in a sort of ‘reverse funnel’.
Don’t start with what data do you have – you don’t know what you want it for yet and you can always manufacture more or buy it in. And certainly do not start in the middle with sexy new analytical fashions that are just begging to be used.
Use a ‘reverse funnel’ to investigate what your analytical processes needs to end up looking like. You can then compare what different analytics methods and software are able to deliver – and what data they need to do so.
Think of your analytical strategy as an array of Business Intelligence telescopes that tell you different things about your customers, your business and your environment. Here’s how Google+ and Facebook are starting to configure their very different arrays of Business Intelligence telescopes on their members.
Indispensable Customer Experience
How many loyalty cards do you have in your pocket? How many loyalty schemes are you a member of? … That’s not very loyal is it? Most loyalty programmes are just bribery in return for customer data.
But if each customer’s experience of a brand, through several cycles of awareness to consumption, was that it was utterly indispensable and an absolute joy to use then they would probably keep coming back. And spend more. And tell their close and trusting friends.
Experience, usefulness and ease are much more valuable to customers than vouchers or loyalty points. Although they mean different things to each customer, so they need to be pre-specified and then configured at the same time as the service is consumed by each customer. Which involves knowing a lot about the customer and producing your service in a very agile manner.
Most importantly, experience, usefulness and ease must be supported across all customer touch points. So they must be a foundation of your omni-channel retail strategy.
Solution: design your omni-channel retail strategy in terms of the customer journey – not just in terms of your sales funnel but by using all that you know about that customer. Use their diverse and changing personal circumstances not some static, aggregated, averaged and frozen history. What they need now and how they need it. Not what some people a bit like them needed at some time in the past.
You also need to segment as low as you can go – it all comes down to segments-of-one in the end because even an off-the-shelf product is consumed according to personal convenience. Every time you segment lower you get a more specific understanding of some customers’ needs and they will value it more.
Retail is being disrupted by lots of new technologies right now. The social media that networks shoppers together in lots of different ways. The mobile devices that people use anywhere and everywhere as well as the apps that run on these devices. And the Big Data that shoppers and supply chains continuously generate.
But the technology is not the problem. The really difficult thing to figure out is how people will use these new technologies. Remember Web 2.0? It only got a name when the different ways that people used it started to settle down a little bit into common patterns.
Now this technological tsunami has reached retail – online and off-line.
What retailers want – E-commerce strategists, CRM Directors, Heads of Marketing, CIOs, Analytics and Insight staff, User Experience teams and Social Media managers – can be boiled down to solving three key business problems:
Fragmentation
Nobody – customers as well as supply chain partners and competitors – has settled on their ‘usual’ ways of using disruptive new technologies like mobile devices, social communications, multi-channel synergies and Big Data analytics.
New hand held devices and web services launch all the time, things keep changing. Everyone is still figuring out how to use them – there is no norm, no ‘usual’. People are still getting used to the features of the devices, apps, sites and new information resources. They are still figuring out what works best for them and what new features they can offer their customers.
This has led to a stage of growing fragmentation – multiple data sources, retail channels, mobile devices, business process silos and brand partners are all variables. They present many different strategic options and opportunities for shoppers, as well as for retailers, and they are so new that there are no obvious or accepted patterns of use yet.
So shoppers, retailers and brand partners are confronted with too many different strategies to comfortably choose between. They also get the slightly disconcerting feeling that they are missing out on some even better ones.
Shoppers have way more sources of advice and new ways to shop than they have needs to satisfy. Retailers have to deal with shoppers who keep changing their customer journey and with brand partners who now interact directly with shoppers at scale, using social media. Also, brand partners now have to deal directly with shoppers’ obscure queries and frank reviews – and be watching out for dissatisfied rants as well as random image-building opportunities.
So in reality, retail is not fragmenting. It’s just that the links that connect shoppers to retailers and the rest of the supply chains are fragmenting. Complexity comes from the number of ways things connect up not from the number of things.
The destination is the same but there are lots of new ways to get there.
Solution: use the vast expertise that comes from your position in the supply chain to give customers and brand partners the advice that’s right for them, i.e. personalised content marketing. Not just what products suit them the best but how these solutions fit into their lives, and the tools and information they need to make the buying decisions themselves. Your position in the supply chain potentially gives you the total knowledge of all your staff, brand partners and past customers.
And also, if its going to fit into your customers’ lives then they need to tell you about their lives…so you get to know them even better.
I love the way that Google+ is an even bigger reason to login and give Google a token to link together all my other interactions with Google products. Each of which tells Google a little bit about what I’m interested in.
Google products are not there to get customers to use the web, they’re there to watch customers use it. I work with loyalty card and customer data firms and Google’s array of products give a much better cumulative view of each customer’s interests than any single big retailer’s loyalty scheme, even those of Tesco Clubcard or Boots Advantage Card in the UK.
Think about those lines of small radio telescopes that you see in the desert. Astronomers combine the data from each of the perspectives of the individual dishes into one big view – and the wider the telescopes are spaced out then the broader the perspectives have access to and the more insight they can gain.
In digital marketing and ecommerce insights are about ‘who’ is interested in ‘what’ products and services, ‘when’ and ‘where’ – even if they do not know it themselves.
Loyalty programmes do a great job of helping to figure this out but their insights are limited by the actual transactions and the relationship that generate the data. For example, an insurance company knows a lot about a customer’s ‘insurance life’ but that’s just like looking through a key hole at the rest of the customer’s life.
Supermarket chains get much broader perspectives than insurance companies because they sell customers things that help them in more diverse parts of their lives. But even that is a small part of their whole lives. Truly indispensible, personal and timely suggestions need to be in the context of large parts of who each customer is and what they do (and what they want to do). Especially if they do not know themselves.
Sure, you could buy-in data but bought-in data is generally more indirect and aggregated than the data that comes from your own relationship with that customer. The more removed from the particular relationship that you want to influence then the less relevant and understandable it is – bespoke always fits better than off the shelf.
Helen Taylor’s post on Econsultancy got me thinking about how Google has developed a very broad array of perspectives on each customer’s life and how it is using Google+ to glue them together and to dig deeper. The +1 button is the simplest way to tell Google what is interesting. But all of Google+’s features help to generate deeper insights and each one gives a subtly different perspective on customers’ interests:
Streams – tells Google different things that the member might be interested in. On timeline to enable insights about trends at the person and group levels.
Circles – tells Google which members might be interested in these different things. Members can segment by some preset categories (Friends,Family,Acquaintances, Following) and define more categories themselves. Analysis of these user-defined categories will give valuable insights into how members thing about their different interests in terms of interest-to-interest associations and higher level groupings of interests (like analysing the category structures of folksonomies and socially generated tag clouds).
Brands can segment by global versus local because its useful for them. So brand partners can also signal to Google what type of members interest them.
Hangouts – helps Google to get the sort of deep insights that only come from closely monitoring small groups of people talking openly. As Helen said, these are panel sessions. The Hangouts On-Air feature enables panel session content to be broadcast, stored and edited. The members and brand partners who choose to view this content are telling Google about their own interests.
The other features of Google+ (and other Google products) are designed to cumulatively generate live and updating ‘process Interest Graphs’, i.e. very wide arrays of perspectives on each member’s life.
Each perspective is a key hole on a person’s life and together they give much more diverse, and deeper, insights for Google’s brand partners than a loyalty programme can – maybe more than Hunch or Gravity can as well. So Google can partner with more brands and do so in more actionable ways.
Facebook, LinkedIn and Twitter have very different ‘arrays of telescopes’ to Google and these give them very different arrays of perspectives to look at their members’ interests from. First, each of these social networks focuses its arrays on different general aspects of their member’s lives. Although they do overlap – and Google+ seems to overlap the most:
Facebook – entertainment and social life, short-term issues, life curation
LinkedIn – work life, short-term issues and long-term projects, network curation
Twitter – all your life, immediate issues, bare bones content
Facebook and LinkedIn have much tighter feedback loops between members – in terms of more levels of connection (ways to directly exchange content) and some features that enable actual two-way conversations.
Twitter is a bare bones way to connect with people who you think might have interesting things to say. Mostly its about broadcasting with some ability for loose two-way communications.
Second, each of these social networks uses different features to get the data that gives them their arrays of perspectives. Google use product-based features outside of their social network, as well as inside like the others.
The bottom line is that they all try to be really useful in their chosen aspect of their member’s lives because they know that being really useful help requires clarification and clarification leads to much deeper customer knowledge than bare transaction data.
Update: Facebook is looking at combining information across its other services here.
The huge data center which runs in the cloud can now connect to you via an app on your smart phone. This set up combines scale and power with precision and personalisation.
Firms are starting to make apps that are really useful helpers for shoppers. Like this one for shoppers at the DIY chain Lowe’s on econsultancy.
These apps are really useful because they can work at ‘global’ as well as ‘local’ scales. They have access to a firm’s worth of data and insights – including those of its partners and customers. But can they also serve up exactly what a specific shopper needs at a specific moment. They combine all-time with real-time.
Of course firms need to get past the data fragmentation barriers of big data, one one hand, and specific customisation requirements, on the other – because each user is a segment-of-one. But phone apps that are powered by big data technology link large scale resources to individual service moments.
The biggest potential benefits of big data come from its ability to act globally as well as locally – it is centralised as well as decentralised.
The implications of this are huge. Firstly, customers need to receive real-time services, i.e. services when they need them not just where they need them. But a real-time experience also means that they can play around with ideas.
Real-time means feedback, iteration and experimentation. A properly designed mobile app can give them suggestions that they would never have thought of. Or they can test out their ideas and compare what works best.
But most of all the local provision of global resources means that apps can be guides – life ‘sat navs’ – that help customers through all sections of the sales funnel. But guides need to accompany the customer, so they need to be immediate as well as continuous, i.e. that’s why they need to be real-time services.
Sandy Pentland of MIT points out some of the key issues about Reinventing Society in the Wake of Big Data here. Data ownership is important because it concerns the main driver, as well as one of the main barriers, to developing Big Data services.
The main driver for developing Big Data services is value creation – not just commercial value for firms and the value that customers get from great services – but also the possibility of sharing some of the value that personal data generates with the person that generated it. It’s the main driver because people commonly do things because they get something in return that they value.
One of the main barriers to developing Big Data services is fragmentation and the fragmentation of ownership is critical. Big Data is the personal diary of everyone and everything. This personal diary is sometimes called the ‘data exhaust’ . It is co-created by customers consuming a service and the service provider as it produces the service. I.e. as all the service provider’s staff and machines produce the service.
But who owns this flow of bi-products, this data exhaust? Is it the service provider? Is it the service provider’s partners in its supply chain, the telecommunication company, the content providers, the payment services partner, the security and authentication partner or others? Or is it the customer?
What makes matters more complicated is that data is always copied rather than consumed. So potentially all stakeholders could use the information – for different purposes. And maybe here lies the solution.
If the value of data depends on its use and it is infinitely copyable then we should be asking who owns the right to use it for specific purposes rather than just asking who owns it? Maybe the problem of ownership fragmentation is a licensing problem. Framing data ownership as a licensing problem may partly help to solve the problem of controlling the use of customers’ personal data as well all the problem of sharing out the value that it can create.
Another Big Data fragmentation problem that Sandy Pentland mentions is that Big Data rarely has one source. It’s nearly always generated on different parts of the firm and partly bought-in from partners – and even in a single firm there are database and business process silos.
Database fragmentation makes it hard to integrate the vast volumes of data even when you are aware of what data is available. It’s another main barrier to developing Big Data services because data services are emergent – they only exist as a whole and they can be combined in many different ways. So its difficult to judge which services will be a success.
It is much easier to start with a good description of customers’ service-needs and then work backwards. But that’s difficult for the firms in the supply chain with tonnes of data and little direct customer knowledge.
That’s why the supermarkets are taking over the world – direct customer contact gives them deep customer knowledge, which helps them to build-up current and new business areas. Then the new business areas give them new insights into different aspects of their customers’ lives – which enable them to build up further new business areas. Look at how Tesco and Sainsbury’s went from groceries to clothes, consumer electronics, then financial services and more services.
If your firm has tonnes of data that you are sure can be leveraged to create new value, but it’s fragmented and you do not know how to use it or when more data needs to be bought in, then I’d suggest using a customer journey analysis approach, like PIGs. Fragmented product and service components always come together at the point of consumption. And anyway, if you want to assess service quality, value is ‘in the eye of the beholder’ – the consumer.
Here’s a video that publicises Rick’s latest project on exploring and explaining the potential of Big Data. Big Data is like the web before we called it Web 2.0 – we’ve got some of the basic technologies but we’re still figuring out what we can do with them.
Rick makes a great point: “Just imagine if your whole life you’ve been looking though one eye, and all of a sudden a scientist created a way for you to look out of both eyes…What if you could open a third eye … or thousands of eyes?”
Big Data gives us access to many new perspectives because Big Data is like the minute-to-minute personal diary of everyone and everything.
Social Graphs connect people that know each other, like social networks. Interest Graphs connect people with what they are interested in. John Battelle’s been writing about them for years. If you can find out what people – retail customers, business customers or colleagues – are interested in then that is the first step to actually giving them what they want.
Interest Graphs and PIGs (Process Interest Graphs) help firms to figure out what each customer is interested in by using their past behaviour, e.g. past purchases, answers to current prompts, the things that people like them are interested in – their social network – and other bought-in data.
Its like when Amazon suggests a book that you really would like to read but you would never have thought of. PIGs are most powerful when they help firms to tell customers what they truly but they would never ever have thought of.
Process Interest Graphs (PIGs) model customers’ lives
But Interest Graphs are not that great at modelling what people need on a timeline, i.e. how their needs have changed and will change in the future. They are more like a stack of photos of one person which have been stapled together in a book. You can quickly flip through the stack of photos to make appear that the person is moving but any one photo is not naturally linked to any other. This makes it difficult to analyse customers’ behaviours based on ‘stream’ or ‘timeline’ data like Facebook are staring to collect with Facebook Timelines. Also, Interest Graphs are fundamentally static so they are not very good at modelling multiple stages of a customer journey – at different timescales of the customer conversion process or different aspects of the relationship with a brand.
The way to solve this problem is to use Process Interest Graphs (PIGs). PIGs model customer journeys by using stream or timeline data at any scale – from second-by-second to year-by-year or higher scales. PIGs can model what people are interested in at any and all timescales because they naturally link to what people are interested in moment by moment. They can also do this for machines, teams and whole organisations, i.e. they scale up for any level of organisational structure as well as for for any timescale.
This means that PIGs can also be used as an overall data architecture for integrating customer loyalty data, CRM data, social network data – any sort of internal or bought-in data. So PIGs are the ‘glue’ for linking fragmented databases, business processes or services.
From the firm’s perspective, they are a basis for multi-channel strategies. From the customer’s perspective they are a basis for a smart phone app that supports all aspects of each customer relationship – both during and between purchases. Here’s a couple of examples.
How do PIGs work?
The thing that makes PIGs different to normal Interest Graphs is that they make it much easier for data to be modelled in terms of ‘customer journeys’. They work on streams, processes and timelines as well as on networks, like social networks and organisations, that link people into static structures. Interest Graphs only work on static structures.
So you can use PIGs to:
PIGs make it much easier to manage customer experiences, and organisations, in terms of customer journeys – i.e. the daily, weekly and longer term lives of your customers, staff, projects, products or services. PIGs can be used to build personal guides for shoppers or they can be a ‘sat nav’ for the work lives of each of your staff.
Loyalty cards are great at linking together the different visits that a shopper makes to a store so that the retailer can build up a better picture of what the shopper is interested in buying. But its like studying the shopper’s life through a key hole – its only about what they do in the store. And they are only in the store for a short time every few days.
Retailers do lots of clever analytics to link up loyalty data with different products, other customers and bought-in data but at the end of the day loyalty cards are a very limited window on a customer’s life. Loyalty data is great for segmenting what is communicated (topic of interest, offers, suggestions, calls to action) and how its communicated (communications media, tone, format, even the colour scheme).
But it is still segmentation – not true personalisation, i.e. it seldom analyses down to a segment-of-one. Loyalty analytics does not give an individualised service. It segments top-down, from the market level down to smaller and smaller segments, so it is inherently standardised rather than bespoke.
This fits the nneds of a centralised marketing function and a centralised marketing function does certain things very well – like planning strategy, whole-business decisions, economies of scale, branding, imagining the future and dealing with the slower business rhythms, like the seasons.
Okay, segmented communications and offers enable a much better fit with different customer types than ‘one size fits all’. But any top-down approach is bad at things like local knowledge, individual customer care, minute-by-minute decisions, customer emergencies, personalised advice, on-the-spot help and solving special problems. And top-down approaches are never very good at what a customer might perceive as sensitivity, agility, emotional support or empathy.
Smart phones + the cloud + apps = personalised + real-time + local
However, more and more of us are buying smart phones and using them to shop. These powerful mobile computers, with the support of a massive cloud-based infrastructure, now allow us to take the web with us wherever we go – 24 hours a day. And a common way to use this technology is an app, which has three game changing characteristics for the Customer Loyalty programmes.
Apps are personalised – the phone identifies the user, it tends to be one phone, or at least one app download per user (because apps commonly store histories of use that are useful for the user, like past searches, play lists or wish lists). Also, the user decides to download an app to a phone, i.e. its pull, not push. So apps are personal in an emotional sense which makes them a powerful tool for understanding each customer in a deeper way.
Apps are real-time – people take their phones with them all the time. People usually do not turn them off when they go to sleep. So two-way interactions with customer via an app can be when the customer actually needs them. Instead of slow responses to monthly direct mail shots they can be fast cycles of answers to prompts that quickly get to the heart of what’s needed right now. They can even use marketing automation like a sort of iterative version of FAQs.
Apps are local – apps know where they are all the time. This is critical for suggesting services that depends on location – which is a lot of services.
So apps are a medium for finding out ‘who’, ‘when’ and ‘where’ a customer is on a potentially continuous basis. Which is a much more powerful way of linking up successive touch points between your firm and its customers than a plastic card – and also a platform for delivering a rich collection of value add services.
Loyalty cards are changing into loyalty apps because their tighter co-creation loop produces greater benefits to both the firms and their customers: more accurate and timely understanding of customer’s needs, for firms, and services that fit the customers better.
Apps enable bottom-up loyalty programmes.
At the moment most apps are just catalogues, they are not the personal guides or ‘life sat -navs’ that they could be. They do not act as personal real-time guides that help customers through repeat cycles of the customer buying process.
But they could do – if they were designed around PIGs – then customers would be loyal because of a brand’s indispensability rather than because a retailer bribes them with money-off loyalty points. PIGs help to model what each different customer is interested in right now.
This would be a bottom-up approach to customer loyalty and CRM. Retailers, and B2B firms, could use apps as their main platform for both CRM and capturing loyalty data. These apps could help each and every customer’s journey; generate loyalty from deep experience and complete indispensability; access infinitely more data; create new modes of product offer and customer service innovation – and appeal to customers that are attracted to mobile technology, like males and young people.
Best of all a bottom-up approach starts with a single customer so it can act as the glue that integrates multi-channel and multi-device strategies.
“Any colour you like as long as it’s any colour you like”
Martin Hayward, dunnhumby white paper, 2009.
If you know what customers want then you can it sell to them or give them great service. Of course there’s the small matter of producing and supplying. But however sophisticated your capabilities are you first need to know what they want, need or are interested in – even if they don’t know it themselves.
The problem is that each individual customer has different needs. You could give them some off-the-shelf product or standardised service – a sort of ‘shotgun’ approach – and it might work for a lot of them. But it would not be a perfect fit for many, you would never satisfy some segments and you will always run the risk of a niche competitor poaching some of your customers.
This is because the greater the fit between your product and the individual needs of a customer then the more they will value it. This applies to everything people use or consume from groceries and clothes to delivery and information services. Fit can be in terms of all product and service attributes: size, colour, look and feel, materials, form, price and all the wraparound services like advice, support, delivery and brand.
Get the fit right and you will get a perfect customer satisfaction score because the customer experience will be great and your product or service will do exactly what that customer requires. But it’s hard because each customer requires subtly different things.
Worse still, what people want changes from second to second. When I’ve had a coffee I do not immediately want another – although my wife will happily chain-drink mugs of tea.
So your understanding of what your customer wants has got to be different for each customer and it must be timely.
So how do I know what each customer wants and when they want it – even if they do not.
Most firms use a mixture of CRM and Customer Loyalty data to get a better idea of what different customers want, whether it’s new products, general product improvements or just things that only apply to the current transaction.
Loyalty programmes, like Tesco Clubcard and Boots Advantage Card, combine loyalty card data with CRM data and bought-in data to segment customers by type and – this is the clever bit – by life stage. For example, if they guess that you are expecting a baby then they invite you into giving much more detailed information (like when the baby is due), in return for much more specific advice (like product suggestions and advice that fits the exact stage of pregnancy that you are at). Sainsbury’s uses Nectar Card data to do a similar thing and IKEA uses Family card data to help people with specific home projects, like a new kitchen.
Key point: loyalty programmes only indirectly tell you what a customer is interested in because they only tell you what customers buy. They tell you nothing about the rest of the customers’ lives – its like trying to study customers lives through a key hole.
But you can use loyalty data to ‘open the door’ and get customers to tell you a lot more about themselves – if you give them something in return. Which does not have to be money-off bribes.
But loyalty cards are changing into loyalty apps. Smart phones provide a massive opportunity to leverage much more personalised data because they are natural platforms for individuality, real-time relationships and location-based interactions. I’ve talked about the opportunities here.
